
La evolución favorece que algunos entre los miles de coronavirus presentes en la naturaleza adquieran diseños que le permitan atacar eficientemente al ser humano.
Sin Embargo
Madrid, 23 de junio (ElDiario.es).- El esfuerzo de la comunidad científica arroja cada día un poco de luz sobre el funcionamiento del coronavirus. Un trabajo reciente, publicado en la revista eLife, ha encontrado que la proteína S (Spike) del virus SARS-CoV-2 contiene una secuencia proteica de 8 aminoácidos (RRARSVAS) idéntica a la de una proteína humana, la ENaC-α. La proteína S, que se encuentra en la envuelta del virus, facilita su entrada a las células humanas para infectarlas. La proteína ENaC-α, que regula el balance de sodio en células epiteliales, es crítica para el correcto mantenimiento de la interfase aire-líquido en los pulmones, y su disminución o disfunción genera problemas respiratorios. Tanto la proteína S del virus como la ENaC-α humana requieren un procesamiento similar para ser activas, y la zona en la que necesitan ser procesadas (la secuencia RRARSVAS) es idéntica. Los autores proponen que, al poseer esta secuencia, el virus competiría por los mecanismos de activación que utiliza la proteína ENaC-α , lo que daría lugar a los problemas respiratorios que observamos en los enfermos de COVID-19.
El análisis de las secuencias de proteínas disponibles en la base de datos de uso abierto (UniProt) determinó que la secuencia RRARSVAS se encuentra en 10 mil 956 de las 10 mil 967 cepas del virus SARS-CoV-2 analizadas, pero está ausente en las proteínas S de todos los otros (más de 13 mil) coronavirus analizados. Foto: NIAID
El trabajo es un buen ejemplo de los resultados que está dando la colaboración internacional y el intercambio de uso abierto en la investigación de la pandemia. El análisis de las secuencias de proteínas disponibles en la base de datos de uso abierto (UniProt) determinó que la secuencia RRARSVAS se encuentra en 10 mil 956 de las 10 mil 967 cepas del virus SARS-CoV-2 analizadas, pero está ausente en las proteínas S de todos los otros (más de 13 mil) coronavirus analizados. Tampoco se ha hallado esta secuencia en otras proteínas humanas. Esta coincidencia, y el hecho de que la secuencia aumente el potencial de infección del virus, puede alimentar las teorías sobre una manipulación humana intencionada, ampliamente difundidas a pesar de no contar con ninguna evidencia científica que las respalde hasta la fecha. Antes de que exploten las teorías conspiranoicas, nos gustaría aclarar lo que implica – y lo que no implica – la presencia de esta secuencia en la proteína S del SARS-CoV-2, y por qué es fácil descartar esas teorías.
Esencialmente, los linajes cambian cuando se alteran sus secuencias de nucleótidos (ADN y ARN), como resultado de procesos naturales o mediante ingeniería genética. Aunque los cambios en secuencias de nucleótidos a veces se traducen en cambios en secuencias de aminoácidos, que dos proteínas tengan una misma secuencia de aminoácidos no implica, ni mucho menos, que las secuencias de nucleótidos del ADN o el ARN a partir del cual las proteínas se sintetizan se parezcan demasiado. Y vamos a explicar por qué.
Las proteínas se componen de cadenas de aminoácidos que se ensamblan a partir de instrucciones contenidas en el ADN (o, en virus como el SARS-CoV-2, en el ARN). El ADN es, a su vez, una doble cadena de nucleótidos de cuatro tipos: timina (T), citosina (C), adenina (A) y guanina (G). Con sólo estas cuatro letras se puede almacenar toda la información necesaria para construir y hacer funcionar un organismo vivo. Para poder utilizarse, la información contenida en la secuencia de nucleótidos del ADN debe ser transcrita a una secuencia complementaria en el ARN, que utiliza tres nucleótidos iguales y uno equivalente: U (uracilo), C, A y G. Estos nucleótidos se agrupan de tres en tres formando los llamados “tripletes” o “codones”. Cada triplete indica el aminoácido que debe añadirse a la proteína en formación. De esta manera, la información contenida en una secuencia de ADN y transcrita a una secuencia de ARN se traduce acorde con el código genético en la secuencia de aminoácidos que componen una proteína específica (figura 1). Para simplificar más la notación y poder escribir secuencias de aminoácidos fácilmente, a cada aminoácido se le asigna una letra mayúscula.
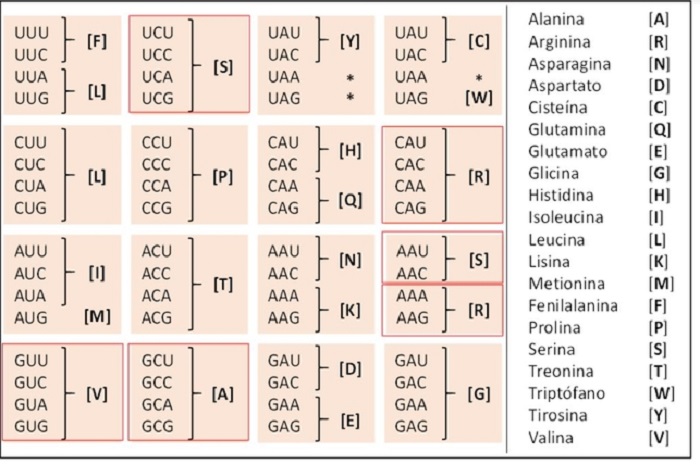
Figura 1: Código genético (adaptado de BioNinja). El ARN en grupos de tres letras (codones), se traduce a aminoácidos (en negrita y entre corchetes). (*) codones que no corresponden a ningún aminoácido. Encuadrados en rojo están los aminoácidos presentes en la secuencia RRARSVAS. A la derecha el listado de los aminoácidos a los que corresponde cada letra. Foto: ElDiario.es
Agrupando los cuatro nucleótidos del ARN (A, U, C, G) en grupos de tres podemos tener 64 combinaciones, pero sólo hay 20 aminoácidos distintos en los seres vivos. Mientras que algunos aminoácidos, como Metionina (M), son codificados por un sólo triplete, otros, como Glutamato (E), son codificados por dos, cuatro, como ocurre con Alanina (A) y Valina (V), o incluso por seis, como los aminoácidos Arginina (R) y Serina (S). A, V, R y S son, precisamente, los cuatro aminoácidos presentes en la secuencia RRARSVAS compartida por la proteína Spike del coronavirus y la proteína ENaC-α humana. En consecuencia hay, nada menos que, 497 mil 664 (6x6x4x6x6x4x4x6) formas distintas de “escribir” la secuencia RRARSVAS con nucleótidos.
Si los autores de este trabajo hubieran encontrado que humanos y virus usaban la misma secuencia de nucleótidos para codificar la secuencia RRARSVAS, habrían concluido que el ARN que codifica la secuencia en el genoma del virus procedía, de una forma u otra, del humano. El título de su trabajo habría cambiado, su interpretación también y habrían publicado sus resultados en una revista de aún mayor impacto, porque habría sido un descubrimiento extraordinario. Desafortunadamente, el artículo no menciona en absoluto las secuencias de ADN/ARN, lo que sugiere que estas no se parecían demasiado (aunque esta información no está detallada en su artículo). Para paliar esta deficiencia, nosotros hemos localizado y analizado, utilizando la base de datos y herramientas de NCBI, las secuencias nucleotídicas correspondientes a estos ocho aminoácidos en la proteína Enac-α humana y la proteína S del coronavirus. Hemos encontrado que las secuencias comparten solamente el 62.5 por ciento de sus nucleótidos (figura 2), un parecido tan pequeño que algunas herramientas de alineamiento ni siquiera encuentran una similitud significativa entre ellas.

Figura 2: Secuencias de ARN correspondientes al fragmento analizado en este estudio. Foto: ElDiario.es
Si quisiéramos modificar artificialmente el virus para ajustar esos ocho aminoácidos de la proteína S y hacer el virus especialmente peligroso para los humanos de forma artificial, tendríamos, en primer lugar, que saber que la proteína S sería más efectiva con ese pequeño cambio. Esto no es nada evidente y ni siquiera está demostrado, ya que el mecanismo de acción que proponen los autores es absolutamente hipotético. Después, habría que manipular el ARN del virus, introduciendo en él 24 letras de ARN humano sin dejar ningún rastro. Esto per se es tremendamente complicado, ya que la manipulación genética en laboratorio deja marcas en la propia secuencia que son fáciles de identificar por otros investigadores. Y sobre todo, si todo esto hubiera sido posible, la secuencia de ARN del virus y la humana deberían ser completamente idénticas, y no sólo equivalentes en términos de traducción a aminoácidos. Con los conocimientos y la tecnología actuales, podemos descartar que la presencia de la secuencia RRARSVAS en la proteína S del virus SARS-CoV-2 sea el resultado de la manipulación intencionada de dicho virus.
Tal como argumentan los investigadores, la explicación más sencilla y probable es que se trate del resultado de la evolución: el virus y los humanos han llegado a soluciones distintas, aunque basadas en la misma secuencia de aminoácidos, para distintas funciones; y el hecho de que tanto las funciones como la secuencia que sirve de base (el ARN y ADN) sean tan distintas indica que se han desarrollado independientemente. El virus posiblemente mejore su infectividad y patogenicidad imitando una pequeñísima porción de una proteína humana. Si tenemos en cuenta que tan sólo una pequeña proporción de los patógenos potenciales consiguen atacar a la especie humana (por ejemplo, tan sólo unos pocos de los 13 mil coronavirus con los que tenemos contacto), no resulta extraño que algunos de ellos hayan dado con una combinación exitosa e innovadora diferente que les permita infectar células humanas y así aumentar su capacidad de proliferar – utilizando el mecanismo responsable de la enorme variedad y complejidad de seres vivos de nuestro planeta: la mutación genética seguida de selección natural.
Con un poco de conocimiento y razonamiento, podemos llegar a la conclusión de que es extremadamente improbable que el SARS-CoV-2 se haya desarrollado artificialmente en un laboratorio (la ciencia es muy reacia a decir “imposible”). Como la continua batalla con otros patógenos (como el VIH y la malaria) lleva años demostrándonos, la naturaleza tiene mecanismos altamente sofisticados sin necesidad de usar nuestra tecnología ni nuestras manos.

Es extremadamente improbable que el SARS-CoV-2 se haya desarrollado artificialmente en un laboratorio. Foto: Achmad Ibrahim, AP





